
Chronos-2: Multivariate Zero-Shot Forecasting with External Covariates
Amazon Research's upgraded model smashed the benchmarks

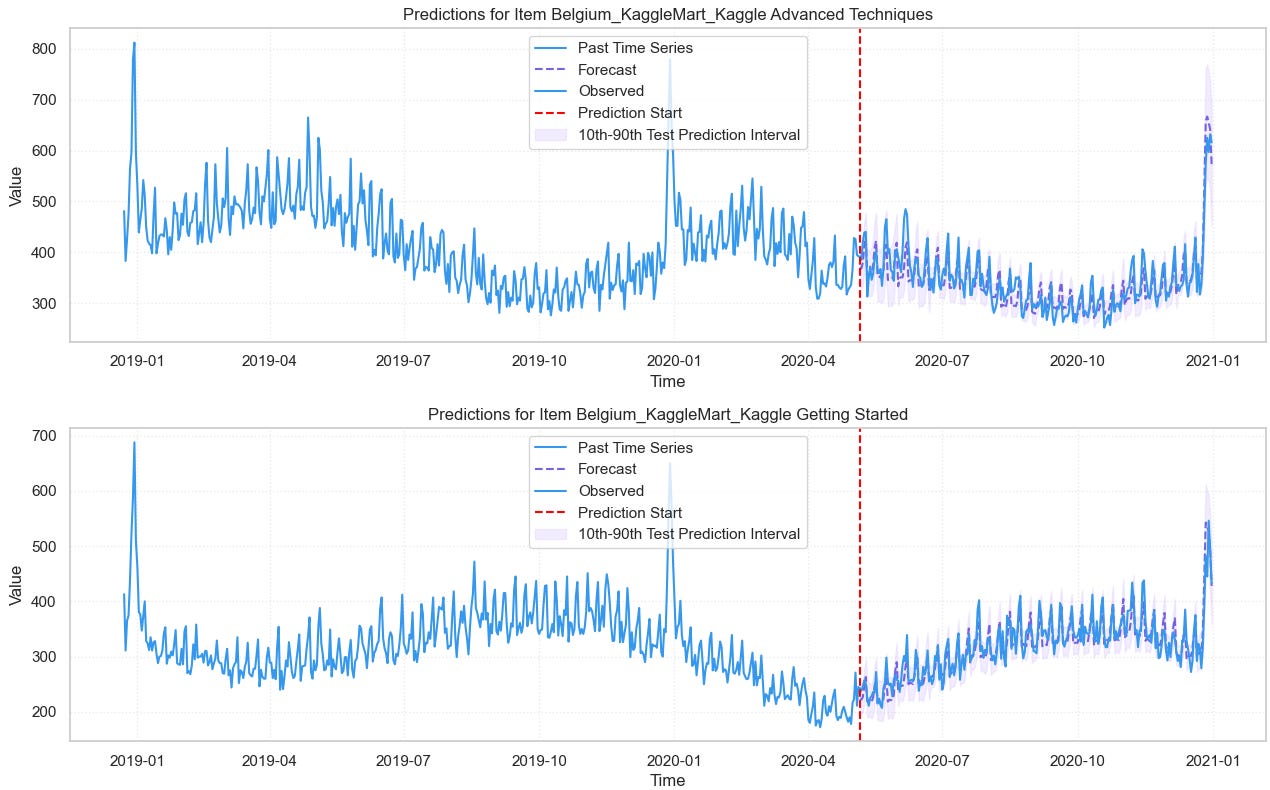
In my previous article, I shared a hands-on tutorial on using Chronos-2.
We explored its 4 forecasting modes and compared them with the best statistical models. Chronos-2, in its multivariate setup with external covariates and cross-learning, achieved the top score overall:
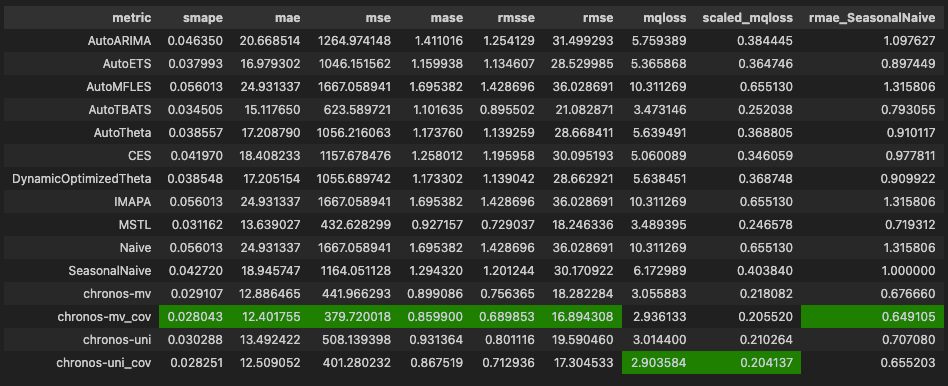
In this article, we’ll dive into Chronos-2’s architecture, explore what makes it unique, and highlight the key elements behind its strong performance.
Let’s get started!
Enter Chronos-2
First, let’s review the key properties of Chronos-2:
Rich inputs: Supports univariate forecasting, multivariate forecasting, in-context learning (with covariates, which can be categorical), and cross-learning (similar to channel-mixing).
Probabilistic forecasting: Forecasts 21 quantiles (q = {0.01–0.99) instead of 9 which most models do.
Variable context and prediction lengths: With a maximum context-length= 8192.
Superior performance: Achieves rank #1 in popular benchmarks, showing that leveraging in-context learning further boosts performance.
Open-source: The model weights (120M parameters) and the pretraining data can be downloaded from HuggingFace.
The biggest advantage of Chronos-2 compared to other foundation models is allowing different forecasting configurations based on covariates:
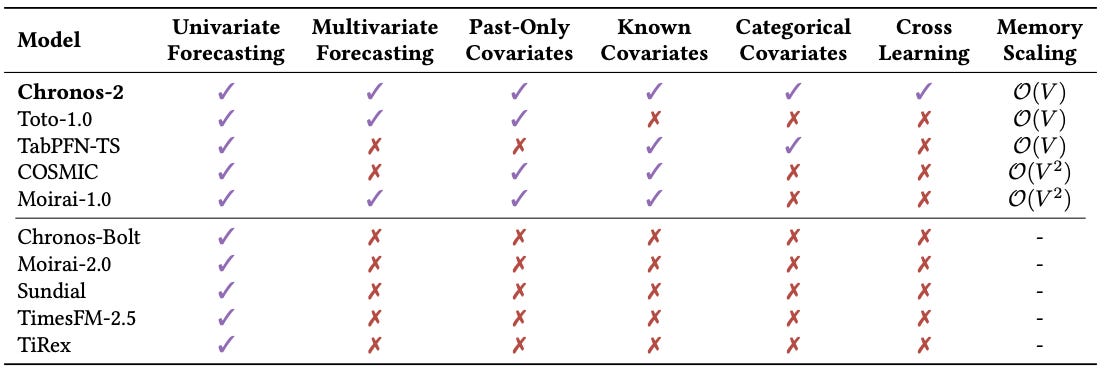
But it’s not just the input diversity driving Chronos-2’s superior performance.
Next, we’ll go step-by-step through the features that make Chronos-2 the best-performing foundation model for time series forecasting.
Chronos-2 Architecture
After testing every foundation model over the past 2 years, I found decoder-only models generally performed better at forecasting.
That might not be the case. Chronos-2 is an encoder-only Transformer model, based on T5’s encoder Transformer block that operates on patches as tokens. For reference, Chronos-1 is an encoder-decoder.
The advantage of an encoder model is that it can seamlessly use future-known inputs like calendar events or promotions—essential for tasks like retail forecasting. Chronos-2 also manages multiple covariate types using 2 attention mechanisms: group attention and time attention, alternating across transformer blocks.
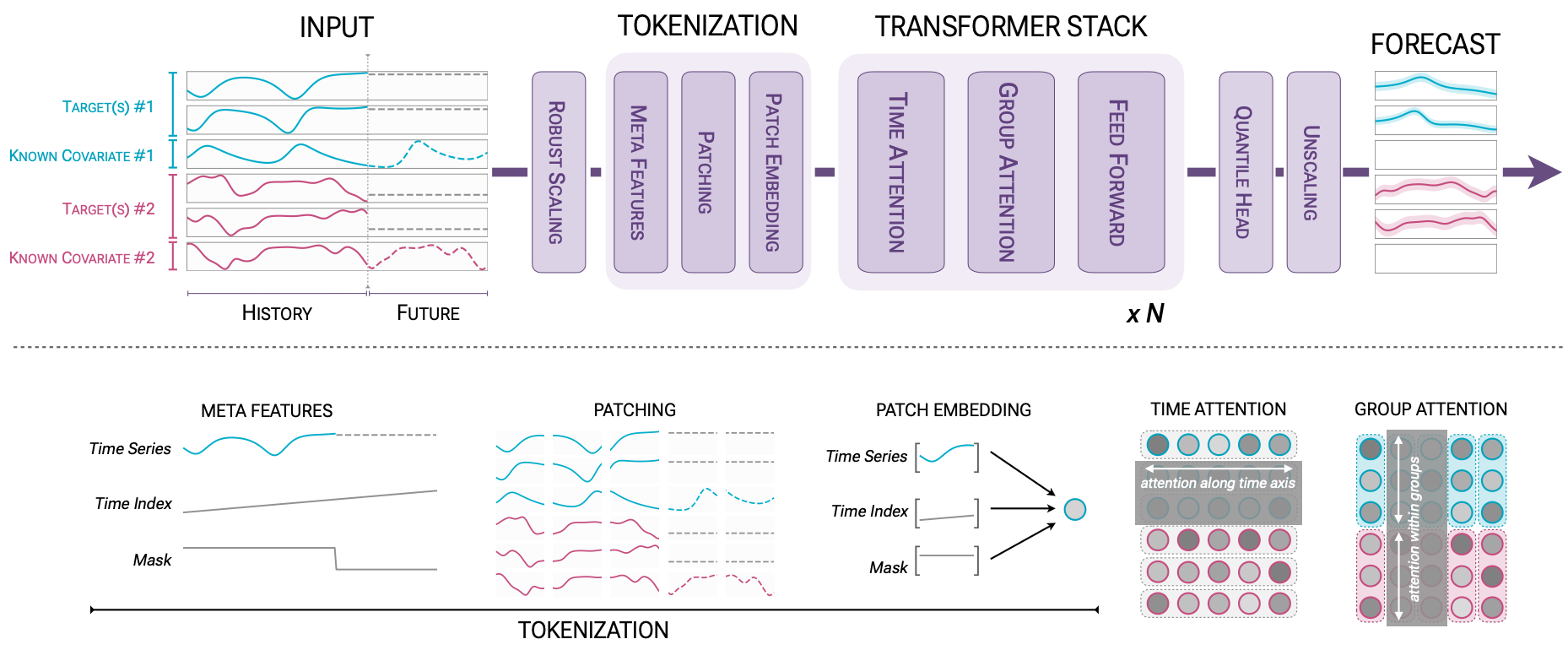
Time attention is standard self-attention applied across the time axis (patches of the same input series). Also, Chronos-2 replaces T5’s relative position embeddings with RoPE embeddings.
Similarly, group attention works across the variate dimension—patches that belong to the same group at a given patch index. Since the order of variates should not affect the output, positional encoding is omitted here.
Let’s go through step-by-step what happens in Figure 1:
Scaling: Standardization is applied to stabilize the scale of each input dimension, followed by a sinh⁻¹ transformation to reduce outlier influence and stabilize variance.
Input construction: Given dimensions T, H, D, M = (context length, forecasting window, number of target dimensions, number of covariates), the model’s input U ∈ (T+H) × (D+M) is constructed by concatenating normalized historical values and future known covariates.
Missing values: Entries corresponding to targets and past-only covariates are set to missing and excluded from normalization. Missing values are replaced with zeros after mask creation.
Meta feature creation: Each input dimension is also appended with a time index, encoding relative temporal position and a mask indicating observed vs missing values.
Patch and embedding Input and meta features are separately split into non-overlapping patches of length
P, padded if necessary, and mapped intoD_model-dimensional embeddings via a residual network. A REG token is inserted between context and future patches as a separator.
That’s it! The sinh⁻¹ transformation is elegant and makes Chronos-2 resilient to outliers.
Some of these steps appear in other models too.
For example, MOIRAI-1 uses Any-variate Attention to model time and feature dependencies, but flattens the input, which limits scalability when covariates are many. Chronos-2 separates this into 2 alternating steps: time (across time) and group (across features) attention.
Toto also alternates between time and space attention (not consecutively though), but as a decoder, it cannot handle future-known inputs with its current architecture.
How Chronos-2 Leverages Covariates
Foundation models so far have focused mainly on univariate forecasting.
Adding covariates isn’t just for show—the authors of Chronos-2 demonstrate that they meaningfully improve performance.
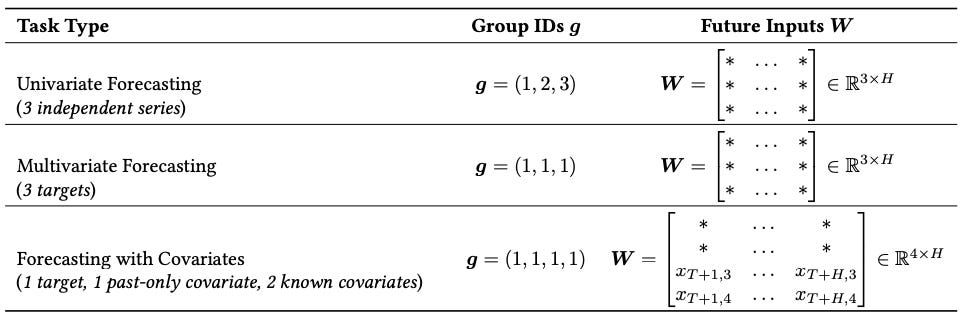
The internal handling of covariates is best understood through how groups are partitioned and how group attention processes them. Chronos-2 supports 3 core tasks:
Univariate forecasting
Multivariate forecasting
Forecasting with Covariates
Time series sharing the same group_id are jointly modeled. The combination of group_ids and the future matrix W defines the task type. For instance, if 3 time series share the same group_id and future inputs are masked, they are jointly predicted—hence, multivariate forecasting. (Table 3)
Chronos-2 also enables cross-learning, where all time series in the batch share information regardless of type (targets, known inputs, etc.), allowing joint predictions for the entire batch.
In my tutorial, where all series fit into a single batch, there are 4 cases:
Univariate
Multivariate (equal to univariate + cross-learning)
Univariate + Covariates
Multivariate + Covariates (with cross-learning)
Also, Chronos-2 also supports categorical covariates: label-encoded if binary, ordinal-encoded if multivariate. Note that these variables are essentially time-varying (dynamic).
A few notes on covariates:
Chronos-2 does not support static (time-invariant) covariates. If you have static metadata, you can group time series that share them—for example, product/store/item combinations can create a grouping of product-store-item and treat them as unique time series. To be fair, the Tiny-Time-Mixers (TTM-R2) model supports all categories in Table 2 and includes static covariates, though it’s less flexible with context and prediction lengths.
Chronos-2 also uses the term in-context learning, but (to the best of my knowledge) it differs slightly from TimeFM-ICF’s approach discussed in an earlier article. In TimeFM-ICF, context examples act like prompts in an LLM and don’t need temporal alignment with the target inputs.
Chronos-2’s cross-learning feature is ideal for cold-start scenarios!
Chronos-2’s Edge in Probabilistic Forecasting
From my early tests, I noticed Chronos-2 produced notably accurate prediction intervals.
Below is an example from my benchmark. The top plot shows TBATS with conformal prediction, while the bottom shows Chronos-2 using multivariate forecasting + covariates + cross-learning:


Even though both models miss the last peak, Chronos-2’s 90th estimated percentile still captures it. The last spike’s height is not predictable given the full context, but Chronos-2 manages to estimate the uncertainty.
Chronos-2’s efficiency in probabilistic forecasting likely comes from 3 factors:
Pretraining to predict 21 quantiles (q = {{0.01, 0.05, 0.1,…,0.9, 0.95, 0.99}}) vs. the usual 9 in other models.
The training objective: Chronos-2 is directly optimized on quantile loss (not MAE/MSE).
Strong pretraining data generation methods (TSI, TCM, KernelSynth).
The third point is very important and worth a deeper look.
Pretraining Chronos-2
The authors of Chronos-2 took training to the next level.
Pretraining happened in 2 stages:
Initially trained with context_length = 2048 time steps
Then, post-trained with an increased context_length=8192 time-steps
Several datasets from GIFT-Eval were used for pretraining. Note that the training splits (GIFT-Train) were also included, so be especially careful to use the correct evaluation splits provided by GIFT-Eval when evaluating on these datasets.
As in previous work, the training data were augmented using the TSI and TCM techniques—upgrades of the TSMixup method used in Chronos-1.
TSI: Synthesizes time series by randomly combining trend, seasonal, and irregular components.
TCM: Generates data from random temporal causal graphs via autoregressive sampling.
One of the main challenges is obtaining multivariate time series data. The authors addressed this by constructing multivariate datasets synthetically—specifically, they created covariates and multivariate data using “multivariatizers” that impose aligned and lagged temporal dependencies among base univariate generators. KernelSynth (first introduced in Chronos-1) was also employed—a highly efficient method used by other foundation models such as MOIRAI-2.
The use of synthetic time series data proved remarkably effective. In an ablation study, the authors found that a variant of Chronos-2 trained only on synthetic data performed only slightly worse than the final Chronos-2 model trained on both synthetic and real data (see Figure 3).
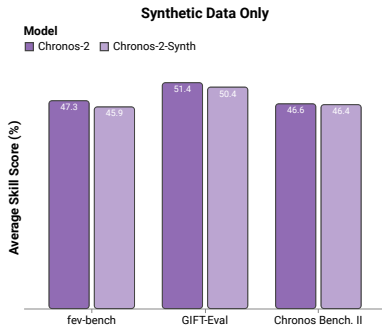
Synthetic data appear to be far more important than initially thought in pretraining time series models. Recently, another zero-shot model (TempoPFN) was released, trained entirely on synthetic data. Similarly, the tabular model TabPFN-2 and its forecasting-based variant TabPFN-TS were also pretrained exclusively on synthetic data.
Evaluation
Next, the authors evaluate Chronos-2 on 3 datasets:
GIFT-Eval Test: Consists of 97 tasks from 55 datasets, emphasizing high-frequency series and long-horizon forecasting. Metrics used are WQL (probabilistic) and MASE (point).
fev-bench: Consists of 100 tasks spanning univariate, multivariate, and covariate-informed forecasting. None of the test tasks were seen during Chronos-2 training. Scaled quantile loss (SQL) is used for evaluation. This is the first large-scale public multivariate benchmark
Chronos Benchmark II: Consists of 27 tasks, mostly short histories (≲300 timesteps on average), focused on short-term forecasting. Metrics used are WQL (probabilistic) and MASE (point).
The evaluation is split into 2 categories: i) using full cross-learning everywhere and ii) isolating the effect of external covariates and cross-learning for each dataset.
Full- benchmark Results
Fev-bench
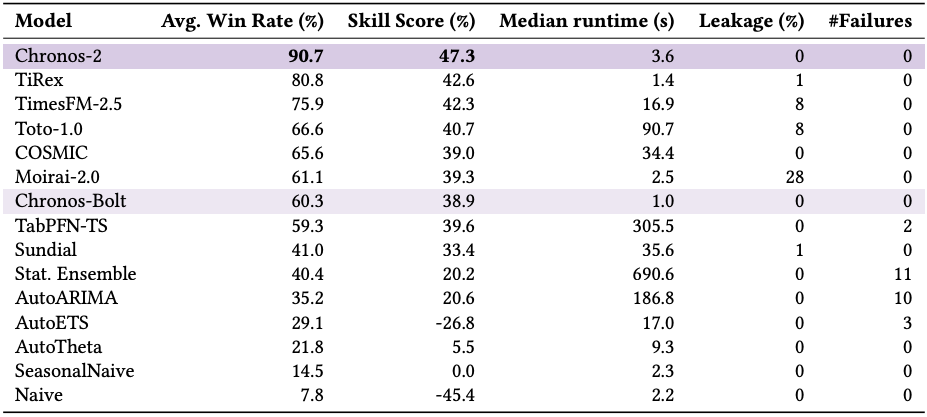
Chronos-2 wins by a clear margin in SQL, showing higher win rates and skill scores than all previous foundation models.
Also, Chronos-2 shows no data leakage with any dataset, unlike other foundation models, making its results even more impressive!
The benchmark includes tasks with covariates, and Chronos-2 maintains its advantage across univariate, multivariate, and covariate-informed settings.
Classical statistical methods like AutoARIMA, AutoETS, and AutoTheta, as well as their ensemble are also clearly outperformed by Chronos-2 and the other pretrained models.
This benchmark is public and contains extra experiments like pair-wise comparisons. You can find it here.
GIFT-Eval-Test
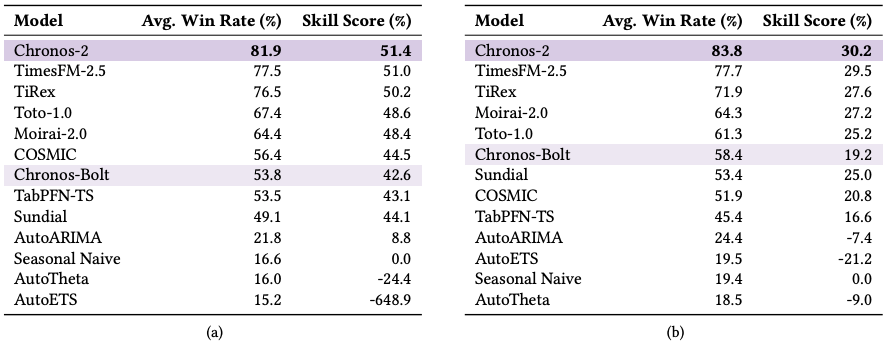
Chronos-2 surpasses the previous winners (TimesFM-2.5 and TiRex) on both WQL and MASE, achieving the highest win rate and skill score.
Chronos-2 shows strong performance on long-horizon and high-frequency forecasting — areas where most models still struggle.
You can find this benchmark here.
Chronos Benchmark II
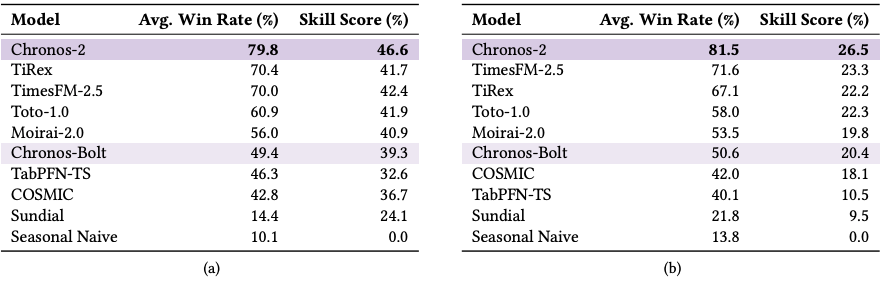
Chronos-2 achieves the best results across all reported metrics (WQL and MASE) on short-history tasks.
None of these datasets were part of Chronos-2’s training data — its strong performance shows how well it generalizes.
Chronos-2 also makes big improvements over its predecessor, Chronos-Bolt, thanks to its updated architecture and new training approach.
Evaluating the Impact of Covariates and Cross-Learning
Chronos-2 offers 2 clear advantages over other foundation models. The authors evaluate these separately to isolate their effects.
Chronos Benchmark II and GIFT-Eval contain only univariate series, so the experiments there measure the effect of cross-learning alone. Think of cross-learning as channel-mixing: univariate series are modeled jointly, sharing information.
To evaluate the effect of covariates, the authors split fev-bench into 3 subsets: univariate (single target, no covariates), multivariate (multiple targets, no covariates), and covariate (including at least one past or known covariate). In the figures below, the light purple bars show Chronos-2 when cross-learning is activated:
Let’s start with the univariate tasks

ICL(cross-learning) consistently improves probabilistic performance on univariate tasks.
The boost is largest on Chronos Benchmark II, which has many time series with short histories.
Cross-learning lets Chronos-2 pool information across related series, which helps most when individual histories are short.
Covariate and multivariate tasks
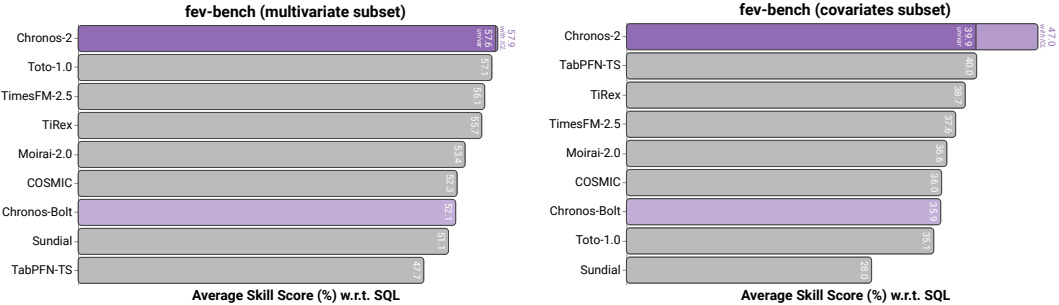
On the multivariate subset, ICL gives only modest gains. Chronos-2 in univariate mode already outperforms Toto-1.0, a native multivariate model. This suggests that, with enough history, a strong univariate model can capture much of the same dynamics.
On the covariates subset, ICL delivers the largest improvements. Chronos-2 effectively uses covariates and outperforms baselines that support covariates (including TabPFN-TS and COSMIC) by a wide margin.
Overall, covariates are where Chronos-2 shows its biggest practical advantage. Multivariate channel-dependence (first examined in the PatchTST paper) helps less often than you might expect.
Retail and Energy forecasting datasets with covariates
The authors also compiled a subset of energy and retail datasets from the fev-bench that includes covariates.
The largest gains from ICL appear on these tasks. Chronos-2 with ICL effectively exploits covariates, outperforming univariate inference that ignores them.

Chronos-2 also beats all baselines by a wide margin. The second-best model is TabPFN-TS, which also supports known covariates. These results highlight Chronos-2’s strength when leveraging covariates.
Now that foundation models enter the covariate and multivariate forecasting arena, it’s time to include the gradient boosted tree models in the benchmarks.
Closing Remarks
Chronos‑2 opens up new possibilities for time-series forecasting with minimal effort.
It lets you generate accurate predictions without the usual obstacles of training from scratch or creating specialized features.
The only thing you need to optimize is the context length, which usually improves performance when increased.
By handling complex, multivariate data naturally, Chronos‑2 shows how modern models can simplify tasks that once required extensive preprocessing and fine-tuning.
Next, we’ll test Chronos-2 on harder datasets like Datadog’s BOOM, which it hasn’t seen before. Stay tuned!
Thank you for reading!
Horizon AI Forecast is a reader-supported newsletter, featuring occasional bonus posts for supporters. Your support through a paid subscription would be greatly appreciated.
References
[1] Ansari et al. Chronos-2: From Univariate to Universal Forecasting
Love the analysis, got me thinking though: is there any way we can check whether the Kaggle data was not used in training? For a regular LLM one way would be try and trick the model into generating specific content (like an opening paragraph of a book we suspect was used), but I can't think of a reasonable analogy for time series.
Hi Nikos this is an excellent article in your current run on LLM models. In a previous post you mentioned that number of observations dictated the utility of LLM based forecasters ( I can’t remember the suggest length 1200 obs?). I wondered if given the cross learning capability of chronos 2 with panel sets of related data if the length of the series could allow it to work better with shorter series than other LLMs?