
Docling: Extracting Structured Data from PDFs and Documents
Part 1 on integrating a chatbot with your personal document collection


Many of my newsletter subscribers ask how I keep up with new research in time series and data science.
Every week, new papers, blog posts, and tutorials come out. Keeping track of them, organizing them, and deciding what is worth reading feels almost impossible. It’s a constant stream of information—99% noise and 1% real value that is easy to miss.
LLMs and chatbots can help with this problem. They are good at reading and summarizing information. At the same time, there is a lot of hype, and it’s not always clear what actually works or how to use these tools well.
That is why I decided to publish my own document intelligence app that I use to store, catalog, and archive useful information. We will go through it as a capstone project, made of 3 parts:
Docling: A library for extracting text, images, and tables from documents into structured and searchable data.
Langchain + Chroma: Making documents searchable with Vector Stores and Retrieval
Interactive Application: Wrap everything into a simple Streamlit app.
Don’t worry if some of these terms are unfamiliar. We will go through everything step by step. Let’s get started!
✅ Find the notebook for this article here: Language Models (Project 2)
Preliminaries
Modern document systems turn messy files into useful answers - but it’s not straightforward.
The idea is this: documents are split into chunks, embedded into vectors, and stored. When you ask a question, the system retrieves the most relevant chunks and passes them to an LLM that produces the final answer. You may have heard of this as RAG, which stands for Retrieval-Augmented Generation.
With RAG, you avoid hallucinations by getting answers based on your local knowledge base rather than on what an LLM has learned. We’ll describe this in more detail in Part 3, but this is an overview of what it looks like:
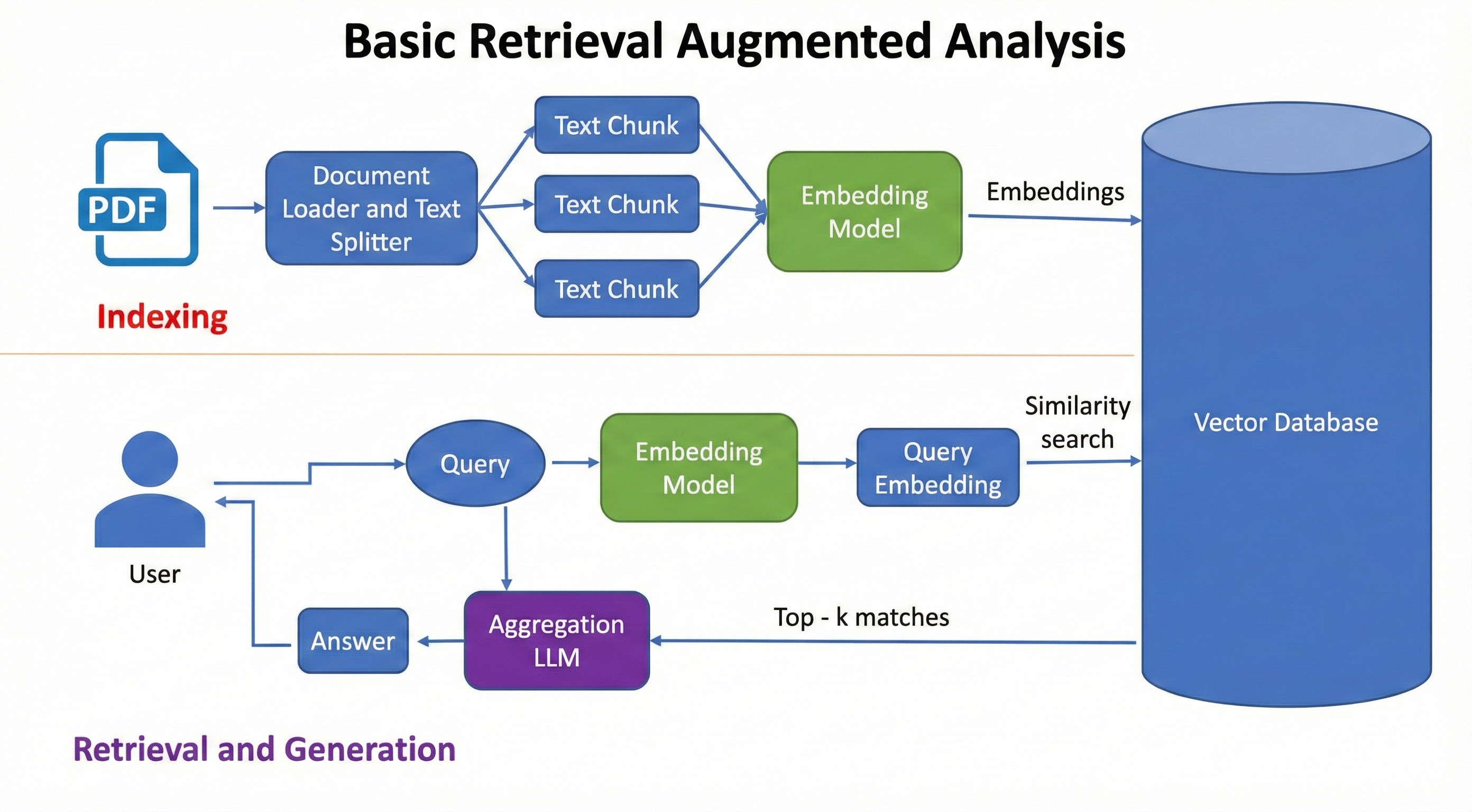
Building basic document retrieval is relatively easy and has been so since GPT-4 came out in 2023. The challenging part is extracting text correctly, since real-world documents contain handwritten notes, tables, images, captions, and broken layouts that are hard to parse and extract correctly.
This is where Docling comes in, as it is built to handle complex documents and produce clean, structured data.
What is Docling? Why Another Document Parser?
Docling is currently the most complete and structure-aware document parsing library available.