
Qwen2-VL: Hands-On Guides for Invoice Data Extraction, Video Chatting, and Multimodal RAG with PDFs
How to use a top, open-source, Vision Language Model.

Note: The primary focus of this newsletter will be time-series — but we’ll occasionally feature interesting models and papers from other areas of AI!
The surge of new LLMs and vLLMs is unstoppable.
One notable model is Qwen2-VL — a Vision LM with advanced image and video understanding.
Key features of Qwen2-VL:
Powerful architecture: Released by Alibaba, it’s built on the Qwen2 LM.
Object and text recognition: Qwen2-VL recognizes complex object relationships, handwritten text, and multiple languages.
Enhanced visual reasoning: The model solves math and coding problems from charts and images, improving real-world data extraction.
Video understanding and live chat: It provides video summarization, question answering, and real-time chat support from video content.
Function calling and visual interactions: Qwen2-VL retrieves real-time data through visual cues, like weather updates.
In this article, we’ll build 3 hands-on guides for using Qwen2-VL for:
Image data extraction
Chatting with videos
Multimodal RAG with PDFs
Let’s get started:
🎁 AI Horizon Forecast is celebrating its 1-year anniversary!
Subscribe by next week to receive a -20% discount and access to my AI Capstone Projects, including hands-on tutorials for Qwen2-VL!
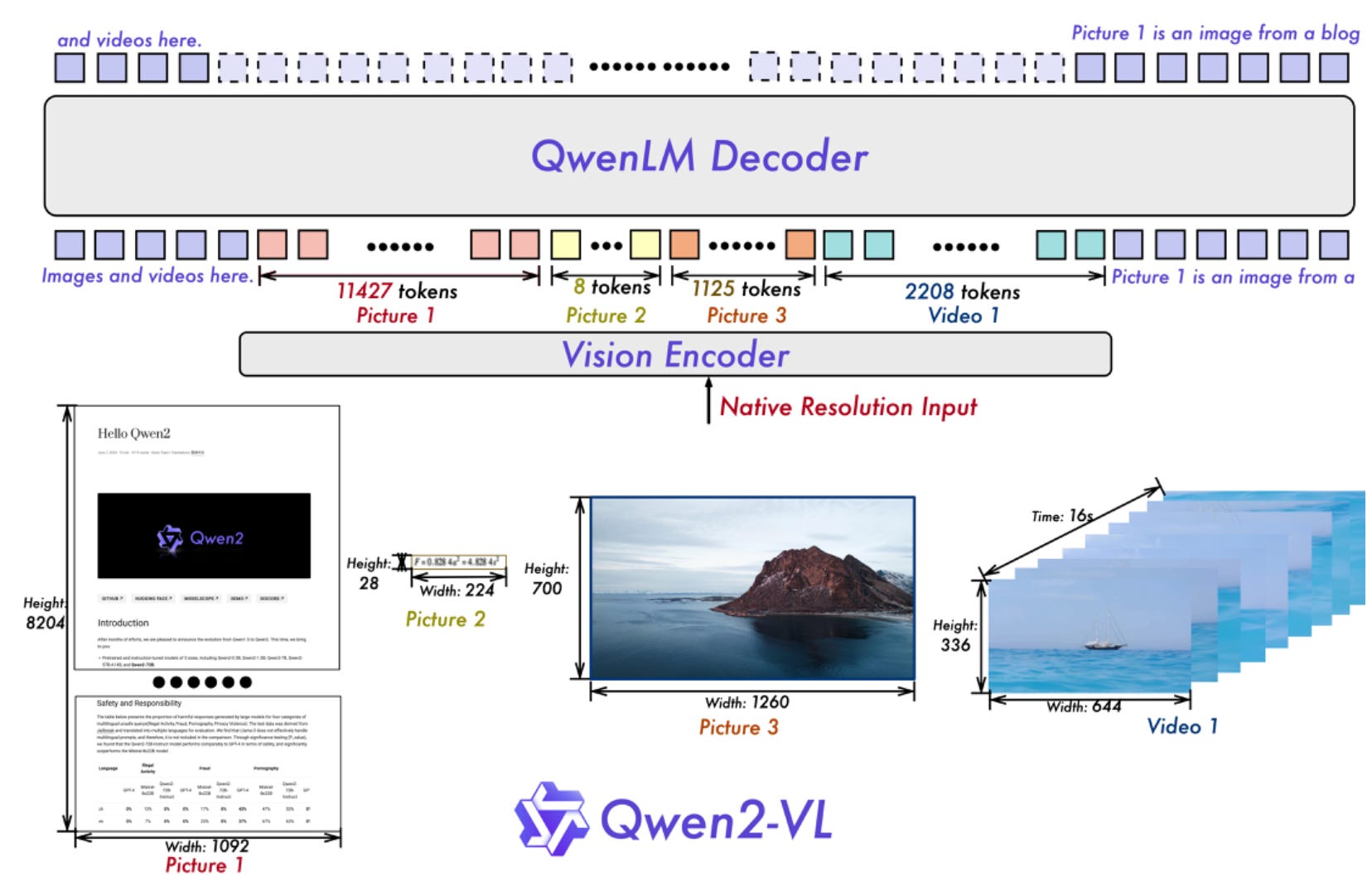
Qwen2-VL Architecture
The image below shows the top-level architecture of Qwen2-VL:
What is known so far is that Qwen2-VL uses Qwen2-LM with a Vision Transformer — capable of processing images and videos.
Also, Qwen2-VL introduces the novel Multimodal Rotary Position Embeddings(M-ROPE). That’s a variant of ROPE embeddings (we briefly discussed them here) that decompose positional embeddings into parts — capturing 1D textual, 2D visual, and 3D video:

Qwen2-VL supports multiple languages, including most European languages, Japanese, Korean, Chinese, and Arabic. More details will be available when the official paper is released.
Note: Qwen2-VL comes in 3 sizes: Qwen2-VL-2B, Qwen2-VL-7B, and Qwen2-VL-72B. The 2B and 7B versions are fully open-source (Apache License). The 72B version is commercial, but free for services with less than 100 million monthly active users.
Let’s now build some projects with Qwen-VL.
Project 1: Invoice Data Extraction to JSON Format
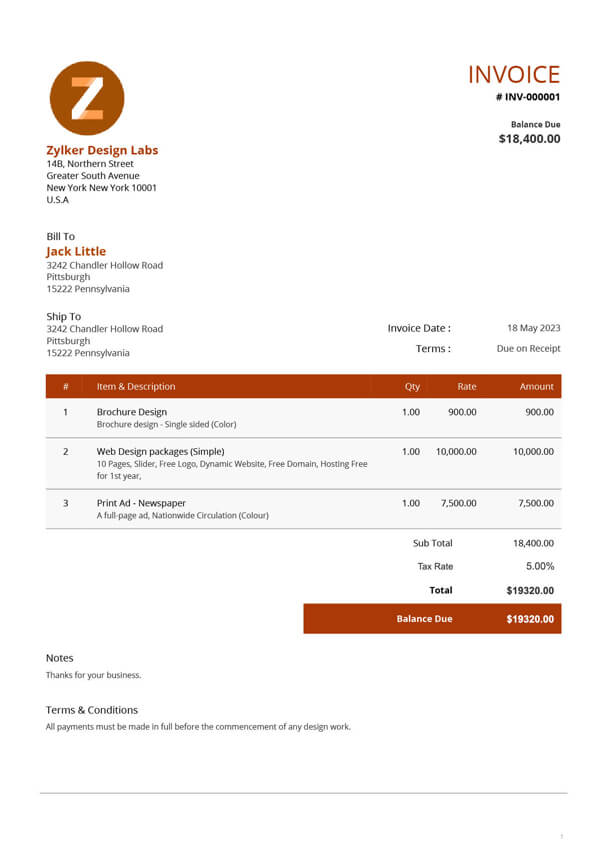
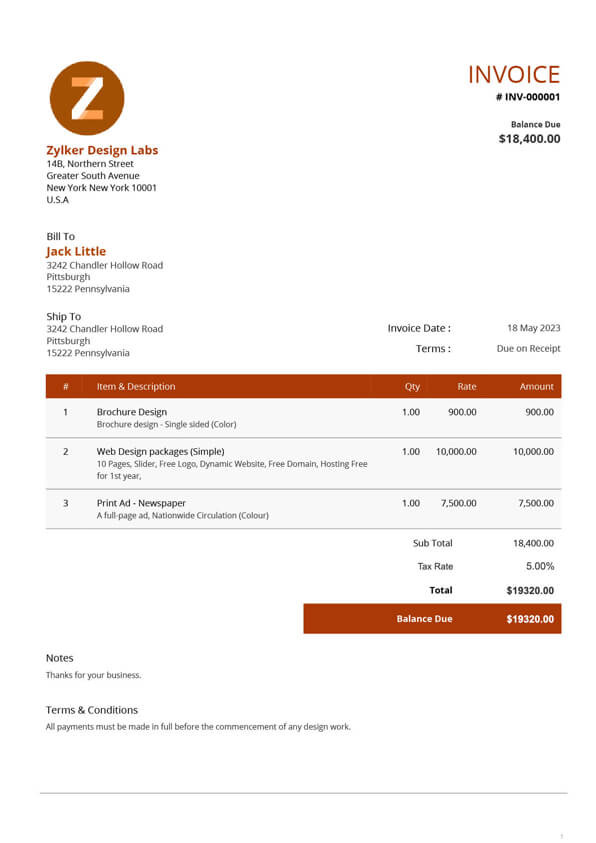
In this mini-project, we’ll extract financial and personal information from the invoice below — in JSON format:
{kind=link}
First, install the necessary libraries:
pip install git+https://github.com/huggingface/transformers accelerate
pip install qwen-vl-utilsNext, we download our file:
import urllib.request
# We will use this sample invoice
url = "https://www.zoho.com/invoice/images/invoice-templates/service-invoice-template/service-invoice-template-1x.jpg"
# Download the file
file_name = url.split('/')[-1]
urllib.request.urlretrieve(url, file_name)
print(f"Downloaded file name: {file_name}")
# Downloaded file name: service-invoice-template-1x.jpgThen, we will install Qwen2-VL-2B-Instruct — the smallest version, less accurate but VRAM-friendly for running on Colab.
Feel free to try Qwen2-VL-7B-Instruct if you have a larger GPU.
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
import json
model_name = "Qwen/Qwen2-VL-2B-Instruct"
model = Qwen2VLForConditionalGeneration.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
processor = AutoProcessor.from_pretrained(
model_name
)After the model is downloaded and placed into memory, we can send our request. Some extra tips:
Use at Least Original Image Dimensions: Ensure you use at least the original size of your image for best results (
resized_heightandresized_width argumentsbelow)Larger Dimensions: Slightly larger dimension sizes in poor-quality images can improve accuracy but will increase VRAM usage. Adjust accordingly:
We’ll use Qwen2-VL’s chat template with the following prompt:
"Retrieve invoice_number, date_of_issue, seller_info, client_info, invoice_items_table, invoice_summary_table. Response must be in JSON format"messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": file_name,
"resized_height": 696,
"resized_width": 943,
},
{
"type": "text",
"text": "Retrieve invoice_number, date_of_issue, seller_info, client_info, invoice_items_table, invoice_summary_table. Response must be in JSON format"
}
]
}
]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
generated_ids = model.generate(**inputs, max_new_tokens=512)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=True)
output_textWe get the following output:
['```json\n{\n "invoice_number": "INV-000001",\n "date_of_issue": "18 May 2023",\n "seller_info": {\n "name": "Zylker Design Labs",\n "address": "14B, Northern Street, Greater South Avenue, New York, New York 10001, U.S.A"\n },\n "client_info": {\n "name": "Jack Little",\n "address": "3242 Chandler Hollow Road, Pittsburgh, Pennsylvania 15222"\n },\n "invoice_items_table": [\n {\n "item": "Brochure Design",\n "description": "Brochure design - Single sided (Color)",\n "quantity": 1,\n "rate": 900.00,\n "amount": 900.00\n },\n {\n "item": "Web Design packages (Simple)",\n "description": "10 Pages, Slider, Free Logo, Dynamic Website, Free Domain, Hosting Free for 1st year",\n "quantity": 1,\n "rate": 10000.0,\n "amount": 10000.0\n },\n {\n "item": "Print Ad - Newspaper",\n "description": "A full-page ad, Nationwide Circulation (Color)",\n "quantity": 1,\n "rate": 7500.0,\n "amount": 7500.0\n }\n ],\n "invoice_summary_table": {\n "sub_total": 18400.00,\n "tax_rate": 5.00,\n "total": 19320.00\n },\n "balance_due": 19320.00\n}\n```']You can use the code below to fix potential errors and format the model’s JSON output:
json_string = output_text[0]
json_string = json_string.strip("[]'")
json_string = json_string.replace("```json\n", "").replace("\n```", "")
json_string = json_string.replace("'", "")
try:
formatted_json = json.loads(json_string)
print(json.dumps(formatted_json, indent=3))
except json.JSONDecodeError as e:
print("Not valid JSON format:", e)
By comparing the results with the invoice above, we notice:
The model’s output is impeccable — it extracts all relevant information accurately!
This was despite the poor image quality and embedded data in tables!
The smaller Qwen2-VL performed well here, but for more complex images or handwritten text, you might need larger models like
Qwen2-VL-7B.
Project 2: Chat with Video
Qwen2-VL can also extract information and interact with videos.
For this project, we’ll use a short YouTube video — a famous scene from Pulp Fiction featuring John Travolta and Uma Thurman’s dance:
## library for downloading youtube videos
pip install pytubefix Download it as follows:
from pytubefix import YouTube
from pytubefix.cli import on_progress
file_name = "youtube_short.mp4"
url = "https://youtube.com/shorts/6MUy21DdnSc?si=-GofdpXBc97pTQ-E"
yt = YouTube(url, on_progress_callback = on_progress)
print(yt.title)
ys = yt.streams.get_highest_resolution()
ys.download(filename=file_name)We’ll use Qwen2-VL-2B again, as it’s less resource-intensive.
model_name = "Qwen/Qwen2-VL-2B-Instruct"
model = Qwen2VLForConditionalGeneration.from_pretrained(
model_name,
torch_dtype="auto",
##attn_implementation="flash_attention_2", #use flash-attention2 if your gpu card supports it (Free Colab's T4 does not support it)
device_map="auto",
)
processor = AutoProcessor.from_pretrained(
model_name
)We define the function chat_with_video, which takes the resized video dimensions, frames per second, and the text message we’ll ask Qwen:
def chat_with_video(file_name, query, video_width, video_height, fps=1.0):
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": file_name,
"max_pixels": video_width * video_height,
"fps": 1.0,
},
{"type": "text", "text": query},
],
}
]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
generated_ids = model.generate(**inputs, max_new_tokens=150)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
return output_textLet’s ask the model:
output_text = chat_with_video(file_name, "What does this video show?", 360, 360)>> ['This video shows a man and a woman dancing on a stage. They are both dressed in formal attire, and the man is wearing a suit. The woman is wearing a white blouse and black pants. The man is dancing in a way that suggests he is performing a dance routine, while the woman is following his lead. The background features a bar with a neon sign, and there are other people watching the performance.']And another question:
output_text = chat_with_video(file_name, "Is the woman in the video wearing shoes?", 360, 420 )>> ['No, the woman in the video is not wearing shoes. She is seen dancing on a stage while wearing black pants.']Surprisingly, the model answered both questions accurately!
A few extra remarks:
Increasing the video’s height, width, and frame rate (fps) generally improves accuracy but requires more GPU VRAM.
Qwen2-VL can handle videos longer than 20 minutes but doesn’t process sound yet.
From my experiments, Qwen2-VL-7B offers the best balance between accuracy and resource requirements (GPU VRAM).
Project 3: Multimodal RAG
In this project, we’ll combine Qwen2-VL with another model, ColPali, to perform RAG with PDFs.
ColPali is a document retrieval model that contains a PaliGemma-3B model (also VLM) and a Gemma-2B. The role of ColPali is to perform the document-retrieval part and create a multi-vector document store:

The pipeline in our case is the following:
Convert each PDF page into an image.
Feed the images into ColPali to store a multi-vector representation for each page.
Submit a text query to ColPali to retrieve the relevant image(s).
Submit the text query and relevant image(s) to Qwen2-VL for the answer.
We’ll use the Byaldi library to create the image vector store. Byaldi loads ColPali (and similar models with the API). We’ll also use pdf2image to convert the PDF into images:
Let’s get started by installing the necessary libraries:
#pip install --upgrade byaldi
pip install byaldi==0.0.5
pip install -q git+https://github.com/huggingface/transformers.git qwen-vl-utils pdf2image## necessary tool for pdf2image
!sudo apt-get install -y poppler-utilsWe’ll download a 4-page PDF for this project — a small file to conserve VRAM.
import urllib.request
# We will use this pdf:
url = "https://studyingreece.edu.gr/wp-content/uploads/2024/05/AUEB-International-Partnerships.pdf"
# Download the file
pdf_filepath = url.split('/')[-1]
urllib.request.urlretrieve(url, pdf_filepath)
print(f"Downloaded file name: {pdf_filepath}")Since the models work with images, not PDF files, we convert each page to an image. If you want to visualize the images in Jupyter/Colab, run this code:
from PIL import Image as PILImage
from pdf2image import convert_from_path
from IPython.display import display
images = convert_from_path(pdf_filepath)
for page_number, page in enumerate(images):
resized_image = page.resize((600, 800), PILImage.Resampling.LANCZOS)
print(f"Page {page_number + 1}:")
display(resized_image)Below is the first image from our PDF:

Next, we load ColPali and build our index store:
from byaldi import RAGMultiModalModel
RAG = RAGMultiModalModel.from_pretrained("vidore/colpali")
RAG.index(
input_path=pdf_filepath,
index_name="image_index", # index will be saved at .byaldi/index_name/
store_collection_with_index=False,
overwrite=True)
The index contains 4 images — one per PDF page. Now, we load Qwen2-VL-2B:
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
import torch
vlm_name = "Qwen/Qwen2-VL-2B-Instruct"
model = Qwen2VLForConditionalGeneration.from_pretrained(vlm_name,
torch_dtype="auto",
device_map="auto")
processor = AutoProcessor.from_pretrained(vlm_name)The function extract_answer_from_pdf performs the following:
Given a text-query, we ask Colpali to retrieve the most relevant image(k=1). The image represents a PDF page.
Given the text-query and the relevant image, we ask Qwen-VL-2B to perform image recognition and provide an answer to our text query:
The function returns the answer (output_text), the page number that contained the answer, and the relevant image/page
def extract_answer_from_pdf(text_query):
results = RAG.search(text_query, k=1)
print(results)
image_index = results[0]["page_num"] - 1
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": images[image_index], ## contains the retrieved pdf page as image
"resized_height": 527,
"resized_width": 522,
},
{"type": "text", "text": text_query},
],
}
]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to(device)
generated_ids = model.generate(**inputs, max_new_tokens=50)
## remove the prompt from the answer
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
return output_text, results[0].page_num , images[image_index]Let’s ask our model:
text_query = "Where AUEB is located?"
output_text, page_number, image = extract_answer_from_pdf(text_query)
print("\n\n")
print(output_text)
print(f"The answer is found in page {page_number} which is:")
display(image.resize((600, 800), PILImage.Resampling.LANCZOS))>>>
['AUEB is located in Athens, Greece.']
The answer is found in page 2 which is:
The model is correct! AUEB University is in Athens, Greece. Interestingly, the answer was synthesized from different parts of the text (notice the green squares)
Let’s ask another question:
text_query = "In which position in Business and Management did the program ranked?"
output_text, page_number, image = extract_answer_from_pdf(text_query)
print("\n\n")
print(output_text)
print(f"The answer is found in page {page_number} which is:")
display(image.resize((600, 800), PILImage.Resampling.LANCZOS))>>>
['The program ranked 150-200 globally in Business & Management.']
The answer is found in page 1 which is:
The model is correct again, identifying the answer in the bottom-right corner of page 1.
Let’s ask one final question:
text_query = "What is the email address and phone number of Thomas Bebis?"
output_text, page_number, image = extract_answer_from_pdf(text_query)
print("\n\n")
print(output_text)
print(f"The answer is found in page {page_number} which is:")
display(image.resize((600, 800), PILImage.Resampling.LANCZOS))>>>
['The email address of Thomas Bebis is tbebis@aeub.gr, and the phone number is 0030 210 8203 295.']
The answer is found in page 4 which is:
Correct again. Feel free to experiment with the model and ask your questions. You can try different languages too!
Can we use multiple PDFs?
Yes! Simply place multiple PDFs in the folder that RAG.index() accesses.
Can we retrieve more than 1 image?
Yes. In this case, we retrieved only the most relevant image (k=1). You can retrieve more by setting k=2, then pass both images to Qwen for processing.
chat_template = [
{
"role": "user",
"content": [
{
"type": "image",
"image": image[0],
},
{
"type": "image",
"image": image[1],
}
{"type": "text", "text": text_query},
],
}
]However, adding more PDFs or retrieving multiple pages requires significantly more resources.
Closing Remarks + Bonus (Llama-Vision3.2)
This article explored Qwen2-VL for image, video, and document retrieval tasks.
For more complex cases, you can opt for the larger or quantized versions of the model — these are reduced in size with minimal loss in quality. You can find them here.
Another interesting use case for Qwen2-VL is fine-tuning (which I may cover in a future article).
Additionally, there are other notable VLMs like Llama3.2-Vision and Aria, including a quantized version of Llama3.2-11B-Vision. If you're outside the EU (yes, EU regulations prohibit Meta’s multimodal models), you can also run my Llama-Vision3.2 notebook, which is available alongside the Qwen projects.
Thank you for reading!
Horizon AI Forecast is a reader-supported newsletter, featuring occasional bonus posts for supporters. Your support through a paid subscription would be greatly appreciated.