
VisionTS: A Hands-On Tutorial for Zero-Shot Forecasting
Using a Pretrained Vision Transformer to Forecast on the ETTm2 Dataset

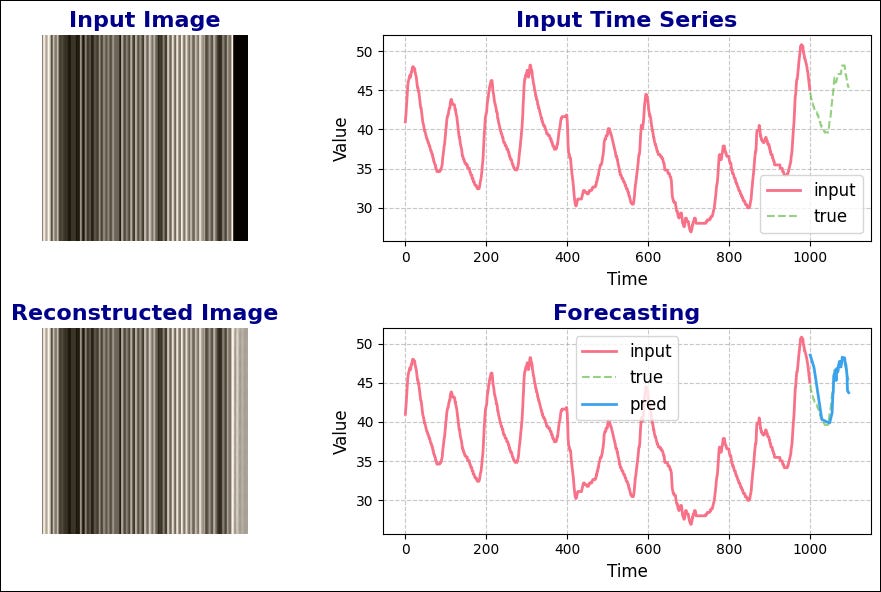
In the previous article, we explained VisionTS, a pretrained Vision Transformer that reframes image reconstruction as a forecasting task.
You can find the theoretical analysis of the paper here:

To recap, here's how VisionTS works:
The key idea here is that in images, pixel variations can be seen as temporal sequences - providing a natural time-series dataset.
These pixel variations display time-series traits like trend, seasonality, and stationarity.
VisionTS uses the visual Masked Autoencoder, a Vision Transformer variant pretrained on ImageNet to reconstruct missing pixels.
It repurposes the image-reconstruction task for forecasting.
The model achieves strong results on various benchmarks and can be further fine-tuned on time-series data for enhanced performance.
VisionTS is a promising model that can be improved in many ways — as we discussed here. Most importantly, it introduces a new paradigm for predictive modeling.
This article will walk through a step-by-step tutorial on using VisionTS. Let’s get started!