
VisionTS : Building High-Performance Forecasting Models from Images
Leveraging the power of images for time-series forecasting - tutorial included


Which is the biggest challenge when building a pretrained time-series model?
Answer: Finding high-quality, diverse time-series data. We’ve discussed this in previous articles.
There are 2 main approaches to building a foundation forecasting model:
“Bootstrap” an LLM: Repurpose a pretrained LLM like GPT-4 or Llama by applying fine-tuning or tokenization strategies tailored for time-series tasks.
“From scratch“: Build a large-scale time-series dataset and pretrain a model from scratch, hoping it generalizes to new data.
While the 1st approach works since Transformers are general-purpose computation engines, it doesn’t yield the best results. The 2nd approach has been more successful as seen here: MOIRAI, TimesFM, TTM, etc.
However, these models seem to follow the scaling laws and their performance depends on finding extensive time-series data — which brings us back to the original challenge.
But what if we could leverage a different modality, like images? This might seem counterintuitive, but some researchers explored this hypothesis and produced groundbreaking results. In this article, we’ll discuss:
How do images internally encode sequential data?
The concept of using a pretrained computer vision model for time series
VisionTS[1], a pretrained Vision Transformer adapted for time-series data.
A comprehensive tutorial on using VisionTS.
Let’s get started:
Find the hands-on project for VisionTS in the AI Projects folder, along with other cool projects! Feel free to check the companion article of the project here.
Why use Images?
Images are a 2D sequence of pixels.
Hence, an image is a pixel array of numerical values — displaying known features of real-world time series, like trend, seasonality, and stationarity. (Figure 1)
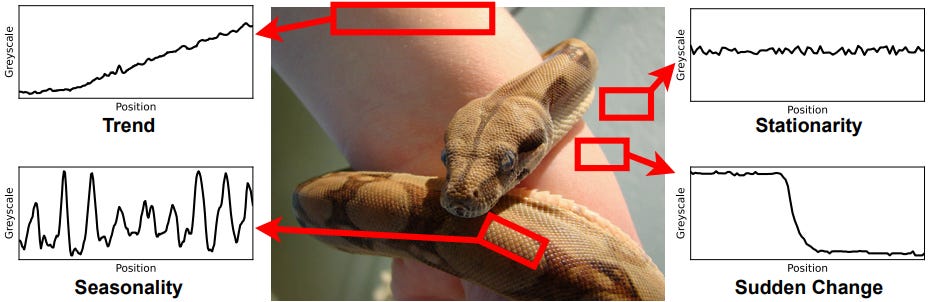
As discussed earlier, pretrained text models (bootstrapped LLMs) have been used to transfer knowledge to time-series tasks but with limited success.
So, what advantages do images offer?
Continuous modalities: Both time series and images are continuous — unlike text which is discrete.
Similar origin: Time series and images capture environmental observations — while text is a cognitive construct.
Comparable information density: Text is dense with meaning, whereas images and time-series data are natural signals with more redundancy.
Images encode sequential information: Unlike text, images exhibit many characteristics of time series (Figure 1).
Thus, images seem like a promising modality. As Yann LeCun mentioned on Lex Fridman’s podcast, text alone is insufficient for building a powerful AGI. Images, being richer and high-dimensional, offer a deeper understanding of the world.
They are also far more abundant than the other modalities — think the amount of data a LIDAR captures and processes in a self-driving car every second.
The question is, how do we create a foundation time-series model that uses images for forecasting?
The plan is to repurpose a pretrained computer vision model and transform the image reconstruction task into a forecasting task — which VisionTS accomplishes.
Masked Autoencoder Visual Transformers
Before introducing VisionTS, we’ll first explain the core mechanism behind it: the visual Masked Autoencoder (MAE)[2].
In simple terms, given a patchified image with some masked patches, MAE attempts to reconstruct the hidden patches (Figure 2):

Here’s how MAE works:
The input image is divided into patches - with around 75% randomly masked.
Only the visible patches are passed to the encoder — typically a Vision Transformer (ViT).
Then, the encoded tokens, along with the masked tokens, are fed into the decoder.
The model is optimized to reconstruct the original image.
Once pretraining is complete, the decoder is dropped.
This process creates a foundation vision model, capable of downstream image recognition tasks.
VisionTS uses the pretrained MAE as its core model. In the next section, we’ll explain how we adapt this model for time-series forecasting.
Enter VisionTS
VisionTS is a pretrained Masked Vision Transformer, which repurposes image reconstruction as time-series forecasting.
Since MAE works with images, we need to convert time-series data into a patchified image for input. After inference, the output is transformed back into a time sequence, producing the forecast. This process is illustrated in Figure 3:

Let’s break down these steps:
Choose a look-back window (of length L) for a time series.
If the time-series has a periodicity (P), segment it into [L/P] patches.
Stack these patches to form a 2D matrix of size (P × [L/P])—essentially, a grayscale image.
The image is normalized.
But, there’s a slight issue: The MAE model was pretrained on ImageNet images fixed at 224 × 224 size, while the 2D matrix is (P × [L/P]).
To align the sizes, we use bilinear interpolation (check the Project’s Appendix for more info), resizing the matrix from P × [L/P] to (N * S, n * S), such that:
The new image consists of patches of size SxS.
N is the number of patches horizontally.
n is the number of visible patches, where n = N * L(/L+H). Remember, L is the size of lookback window, and H the horizon(prediction length). The number of visible patches is thus determined by the ratio of context length to horizon.
Therefore, the new aligned image has (N x n) visible patches and N x(N-n) masked patches. In the example of Figure 3, the image contains 7x6 visible patches and 7x1 masked patches.
The masked patches array is fed into MAE, which outputs the decoded patches.
Finally, we reverse the process (bilinear interpolation, de-normalization, and flattening the image) to convert the decoded patches back into a 1D sequence—our final forecast.
In summary, pretraining MAE on ImageNet is straightforward. The novelty of VisionTS lies in leveraging MAE for time-series forecasting.
Benchmarks
Next, the authors put VisionTS to the test.
They compare VisionTS with other foundation, DL, ML, and statistical models. They test VisionTS as a zero-shot forecaster (predicting unseen data) and explore few-shot tuning (how training on a small data portion improves performance).
Monash Benchmark
First, VisionTS is compared with other models using the Monash dataset.
Figure 4 shows the aggregated results from 29 Monash datasets (on their test sets). They calculate normalized MAE (each dataset’s MAE divided by the Naive Forecast’s MAE). Only llmtime and VisionTS are zero-shot forecasters — the others are fully trained.
Notice that MOIRAI, another pretrained model, isn’t classified as zero-shot here because it was trained on all but 2 Monash datasets.
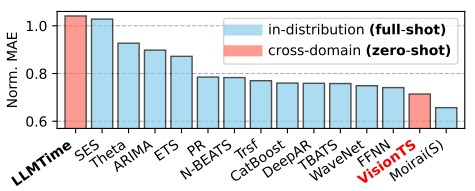
Key findings:
VisionTS ranks second, indicating the potential of using computer vision models for time series.
MOIRAI-small performs best, although it was technically fine-tuned.
The authors only use MOIRAI-small — it would be interesting if they had included the larger versions as well.
Regardless, pretrained time-series models have great potential.
Long Horizon Benchmark
Next, VisionTS is tested on long-horizon forecasting using the Informer benchmark.
Here, the authors compare VisionTS (as a zero-shot forecaster) with other DL/ML models (these are fine-tuned on 10% of the target datasets). The performance metrics are MAE and MSE (Table 1):
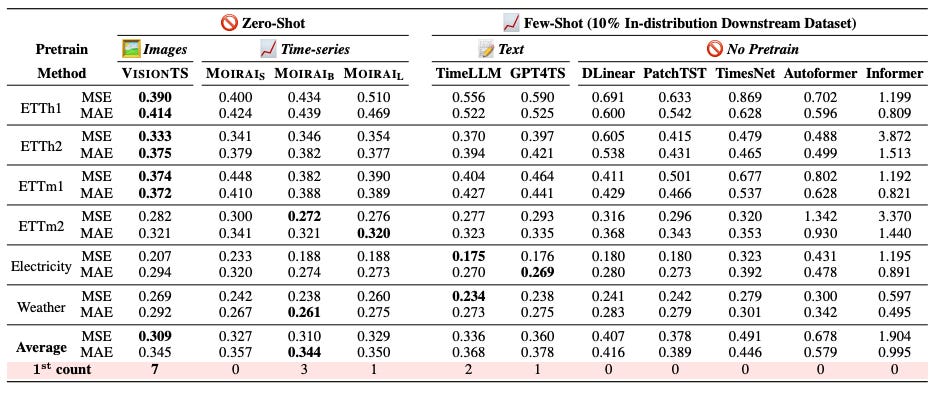
Important Findings:
VisionTS scores best overall, with the most wins.
Pretrained models (on images and time series) generally perform better.
The Monash datasets used here (Weather and Electricity) weren’t part of MOIRAI’s pretraining, making MOIRAI zero-shot in this case.
Informer, Autoformer, and DLinear are not foundation models. Full training of these models would improve the benchmark's competitiveness, although the authors later share fully trained results (Table 2).
VisionTS was also tested after fine-tuning. The same setup was used, but models were now fully trained on the datasets. VisionTS was lightly fine-tuned (1 epoch on average, updating only layer normalization).
The results are shown in Table 2:
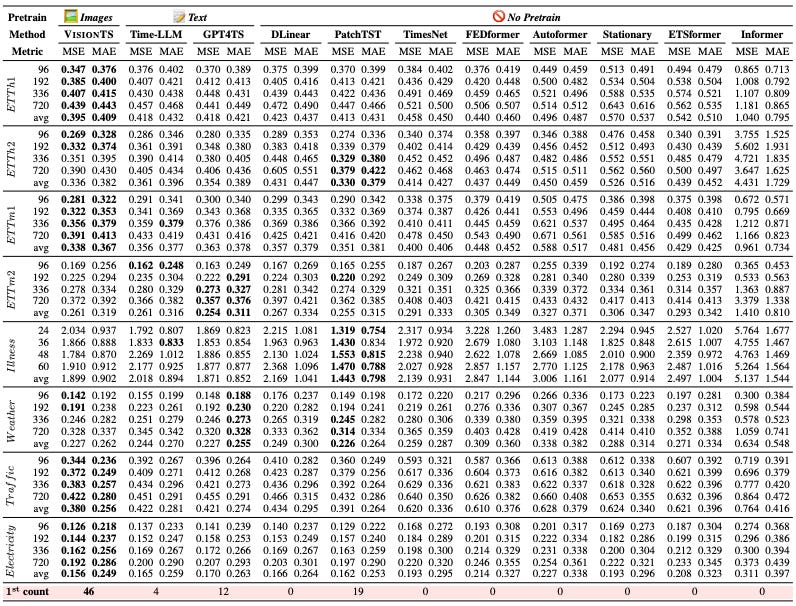
Key takeaways from both tables:
Again, VisionTS ranks first and scores the most wins.
Fine-tuning significantly improves VisionTS, except for minor gains in ETTh1 and ETTh2, likely due to lower frequency.
Zero-shot VisionTS doesn’t outperform all models individually trained on each dataset, but minimal fine-tuning yields major improvements.
Note: The authors also examined how context length affects performance (Figure 5). They found that performance improves with longer context lengths, especially in high-frequency datasets. This aligns with other pretrained models like MOIRAI (see here). In general, context lengths >1000 are usually beneficial :

Impact of Parameter Size
The authors explore how parameter size impacts performance.
Larger Transformer models generally benefit from scaling laws, as discussed extensively in earlier work. For VisionTS, they benchmark MAE’s performance with different model sizes:
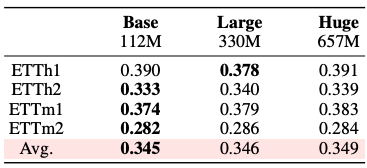
The authors test the following sizes: Base(122M parameters), Large(330M), and Huge(657M).
Interestingly, the Base model performed the best — because the larger models overfitted on image-specific features, reducing their transferability. Remember, VAE is pretrained on the Imagenet-1k dataset, a relatively small dataset by today’s standards.
Comparing with Traditional Models
Many modern time-series models skip comparisons with traditional statistical models, viewing them as trivial.
However, statistical baselines remain valuable and, in some cases, outperform more complex models. The authors included a few statistical models for comparison (Table 4):

VisionTS clearly outperforms the statistical models. Although the paper doesn’t specify their configurations, it would have been helpful to include more competitive versions like Nixtla’s AutoARIMA, AutoETS, AutoCES, and DynamicOptimizedTheta —or the Statistical Ensemble which is very competitive.
Regardless, VisionTS’s zero-shot performance is impressive.
Closing Remarks
VisionTS is a groundbreaking time-series foundation model, delivering impressive forecasting results.
However, there are still areas for improvement. Currently, VisionTS is limited to univariate time series and its scalability—how it performs with more data, time, and parameters—has not yet been explored. The authors recognize these limitations and suggest them as future research directions.
Despite this, VisionTS demonstrates that images can be a powerful modality for time-series forecasting, potentially outperforming text-based approaches. There are clear next steps to enhance this model: i) pretrain MAE on a larger image dataset, ii) further pretrain MAE on time-series data, and iii) explore architectures beyond the Vision Transformer.
We'll be closely following the exciting developments in this approach to time-series modeling—stay tuned!
Thank you for reading!
Horizon AI Forecast is a reader-supported newsletter, featuring occasional bonus posts for supporters. Your support through a paid subscription would be greatly appreciated.
References
[1] Chen et al. VISIONTS: Visual masked autoencoders are free-lunch zero-shot time series forecasters (August 2024)
[2] He et al. Masked Autoencoders Are Scalable Vision Learners