
Transformers, Time Series, and the Myth of Permutation Invariance
Beware the false prophets of forecasting!

After many years of blogging about time series, 𝗼𝗻𝗲 𝗺𝘆𝘁𝗵 𝗷𝘂𝘀𝘁 𝘄𝗼𝗻’𝘁 𝗱𝗶𝗲.
That Transformers shouldn’t be used for forecasting because attention is permutation-invariant.
This is misused. Since 2020, nearly all major Transformer forecasting models encode order through other means or redefine attention itself.
Google’s TimesFM-ICF[1] paper confirms what we knew: Their experiments show the model performs just as well with or without positional embeddings. (Figure 1)
Sadly, the myth will live on—kept alive by influential experts who sell books and courses to thousands. If you’re new, remember: Forecasting Transformers are just great tools, not miracles or mistakes.
In this article, we’ll take a closer look at this myth and examine what’s true and what isn’t.
✅ Find a tutorial notebook on TimesFM, along with other cool projects here: AI Projects Folder (Project 24)
Preliminaries
Let’s start with the basics — what is attention?
Given a sentence, attention calculates the relative importance of each word compared to every other word, as pairwise scores.
The attention mechanism isn’t new. It’s mathematically equivalent to kernel regression (the Exponential Dot Product), but without gradients [Nadaraya-Watson, 1964]. Let’s see how it works:
Consider the sentence “music inspires emotion“. Figure 2(top) shows the full-attention matrix weights, where a<i,j> is the attention between words at positions iand j.
Now, let’s permute the words to create the sentence “emotion inspires music“. Since attention is calculated as pairwise scores between words, we can also permute the respective attention weights (Figure 2 bottom):

Therefore, while the 2 sentences have different meanings, their permutation leads to the same attention scores — hence attention is permutation invariant.
That’s why we add extra components to encode position. The original Transformer used absolute position encodings.
Back to time-series. Since attention is permutation-invariant, and order is crucial in time-series (even more than in NLP), why use it at all?
The answer is simple: there are different types of attention — and they behave differently.
Enter Causal Attention
Figure 2 illustrates a particular type of attention, known as quadratic self-attention.
This form is used by masked, encoder-only models (Figure 3, top). But with the rise of LLMs, attention has evolved fast.
The key idea behind the newer variants is causal attention, used by modern decoder-only models (LLMs) (Figure 3, bottom).
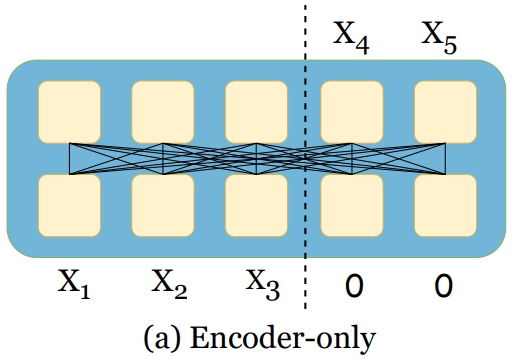
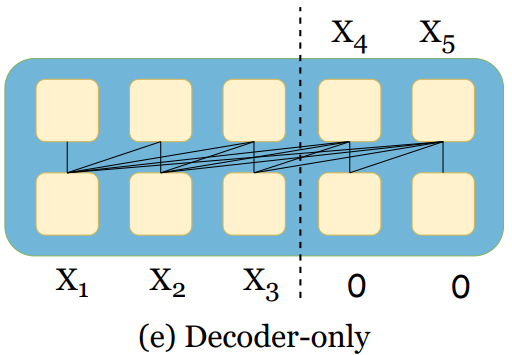
Self-attention models use bidirectional attention (looking at past and future context). They excel at tasks like imputation and anomaly detection.
Causal-attention models use unidirectional attention (looking only backward) to predict the next value in a sequence, making them suitable for generation (forecasting).
However, recent research has shown that each type of attention has different properties, one of which is related to positional embeddings.
We’ll discuss this next.
Enter TimesFM-ICF
Google’s TimesFM-ICF paper revealed something remarkable—yet counterintuitive (at least to those new to this space).
TimesFM-ICF, a decoder-only foundation model using causal attention, performs just as well with or without positional embeddings.
This happens for 2 main reasons:
Causal attention (unlike standard self-attention) implicitly encodes positional information once a single Transformer layer is present. This effect compounds in a well-pretrained, generalizable model.
MLPs within each Transformer block inherently capture positional patterns. That’s why linear DL models like TSMixer are also successful.
Let’s discuss both reasons in detail
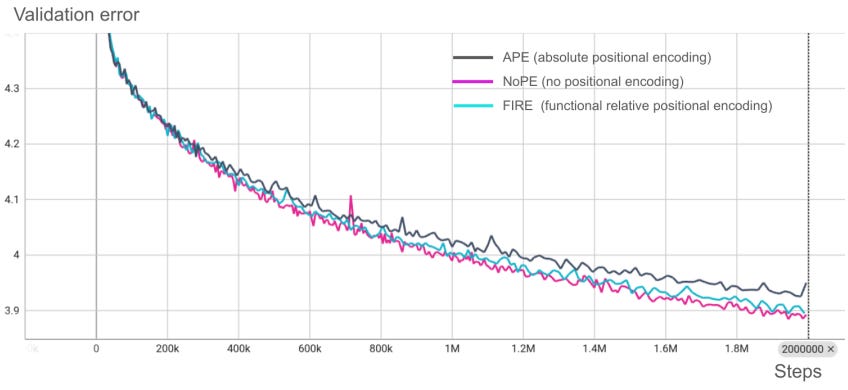
The first reason comes from another paper [3], which TimesFM-ICF references. In it, the authors test how positional embeddings affect GPT-2—also a decoder-only model.
Although the figures differ slightly, there’s a small but noticeable gap in GPT-2 performance with and without position embeddings. However, in forecasting models, another factor comes into play.
From time series DL papers, we know MLPs also help capture positional information. The TSMixer authors highlight this: “The time-step-dependent linear model, despite its simplicity, proves to be highly effective in modeling temporal patterns.” [4]
That’s why forecasting models often add extra MLP layers (more than NLP Transformers of similar size) to better model temporal dynamics. TimesFM, for example, includes additional input and output embedding MLPs.
Therefore, adding extra MLPs bridges the performance gap between Figure 4 and Figure 5 (the small difference with or without embeddings).
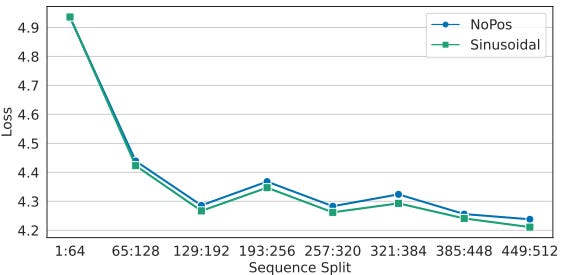
Fortunately, NoPE setup brings key advantages during pretraining:
Better length generalization — crucial when extending context windows with in-context examples, as NoPE models handle longer prompts more gracefully.
Semantic consistency — removing absolute encodings avoids a mismatch between base model training (without examples) and continued pretraining (with added context), preventing positional drift.
No accuracy trade-off — empirically, NoPE maintains validation performance comparable to advanced length-generalizing encodings like FIRE.
Therefore, we can conclude:
Evidence shows that decoder-only, pretrained time-series models can perform equally well without positional embeddings. Attention alone drives performance, enabling flexible context and prediction lengths.
The Pre-2024 Era
Decoder-based Transformers for forecasting are mostly a recent trend—but what came before?
Most early Transformer forecasting models were encoder-based, encoding position through alternative mechanisms. For example:
Hybrid architectures: Models like TFT used an LSTM encoder-decoder to capture local dependencies.
Feature-based attention: Models like iTransformer applied attention across features (variates), not time.
I’ve discussed these architectures in more detail here:


Many of these earlier models showed limited improvement over simpler deep learning approaches. But that wasn’t due to attention’s permutation invariance—it was overfitting, as the TSMixer paper explains [4].

Put simply, these models were trained on toy datasets—too small for a Transformer’s capacity.
By contrast, foundation time-series models, trained on trillions of tokens, do leverage attention effectively. When that attention is causal, performance soars—often surpassing even supervised models (Figure 6).
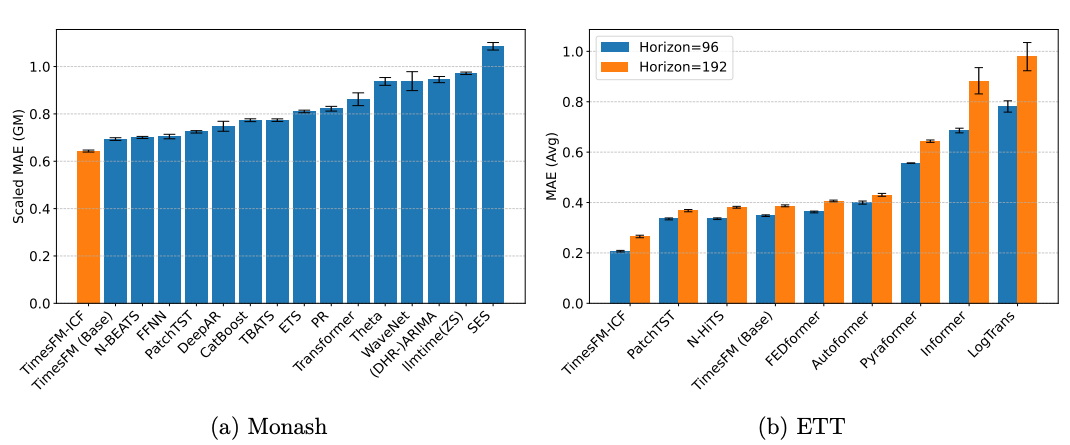
I’ll skip the deeper details here. You can find more in my previous article on TimesFM-2.5 and TimesFM-ICF.
Ignoring the Noise
Until proven otherwise, causal attention remains superior to self-attention for time-series forecasting at the current scales we study these models.
Yet, some papers attempt to claim otherwise. One example, shown in [5], appears at first glance to contradict the findings of TimesFM-ICF, suggesting serious limitations in the model:

Here’s the catch, though: This paper studies self-attention, and specifically linear self-attention.
While the authors present valuable theoretical insights, their findings are largely irrelevant to the current state of the art. Moreover, they fail to cite the TimesFM-ICF preprint, published nearly a year earlier.
Closing Remarks
Normally, I wouldn’t bother publishing an article like this — these distinctions should be obvious to any impartial, well-informed practitioner.
My goal is to bring clarity and help you focus on what truly matters.
After all, Transformers aren’t a silver bullet; they’re just tools — powerful ones, but only when used in the right context!
Thank you for reading!
Horizon AI Forecast is a reader-supported newsletter, featuring occasional bonus posts for supporters. Your support through a paid subscription would be greatly appreciated.
References
Das et al. In-context Fine-tuning for Time-series Foundation Models (ICML 2025)
Shen et al. The Power of Architecture: Deep Dive into Transformer Architectures for Long-Term Time Series Forecasting
Havivτ et al. Transformer Language Models without Positional Encodings Still Learn Positional Information
Chen at al. TSMixer: An All-MLP Architecture for Time Series Fore-
Zhou et al Why Do Transformers Fail to Forecast Time Series In-Context?
Couldn't agree more. That "one myth just won’t die" is spot on. It's wild how some folks cling to old narratives, especially when solid papers like TimesFM-ICF clearly show the way forward. Guess those "influential experts" have a lot of content to update. Much apreciated!
Thanks for the good 😊