
TSMixer: Google's Innovative Deep Learning Forecasting Model
Combining lightweight design with high forecasting accuracy


Many DL forecasting models tend to follow AI trends.
But not TSMixer. Released by Google almost a year ago, it has gained significant traction and is widely used as an alternative to traditional ML-based models, thanks to these advantages:
Lightweight: Its MLP-based architecture efficiently captures patterns in both time and feature dimensions.
Multi-Purpose: The TSMixer-Ext variant accommodates historical data, future known inputs, and static exogenous variables.
Multi-Channel Modeling: It leverages cross-variate information—its feature-mixing MLPs enable joint learning of interdependencies across covariates.
Superior Long-Term Forecasting: Capable of handling longer contexts, it excels at forecasting horizons up to 720 data points, as benchmarks show.
These characteristics make TSMixer a versatile choice for domains like demand planning, retail, and financial markets.
Let’s get started!
✅ Find the hands-on project for TSMixer in the AI Projects folder (Project 8), along with other cool projects!
You can also support my work by subscribing to AI Horizon Forecast:
Enter TSMixer
TSMixer is an MLP-based Deep Learning model designed to process both time and feature dimensions—capturing temporal dynamics and cross-variate information.
The top-level architecture of TSMixer is illustrated in Figure 1:

TSMixer utilizes 2 mechanisms: Time Mixing and Feature Mixing. Let’s explore these with an example. Imagine a dataset of 3 time series, where y is the target variable and x, and z are observed covariates. For an input size T, the sequences are formatted as:
y1, y2, y3 … yT
x1, x2, x3 … xT
z1, z2, z3 … zT
where y1 is the target variable at t=1, y2 at t=2 and so on.
Time Mixing applies an MLP across the time dimension, while Feature Mixing across the feature dimension.
Thus, with Time Mixing, the sequences are processed as:
<y1, x1, z1>, <y2, x2, z2> … <yN, xN, zN> and so on
And with Feature Mixing:
<y1,y2,y3, … yN >, <x1,x2,x3, … xN >, <z1,z2,z3, … zN >
This double-mixing operation is simple, yet very effective. For enhanced performance, N blocks of time-feature layers can be stacked.
Normalization in TSMixer
Moreover, TSMixer uses 3 types of normalization. Assuming the input data has shape x=<batch_size, sequence length, features>, we have:
Batch Normalization: Normalizes over the batch and time dimension for each feature (x.mean(dim=(0, 1))
Layer Normalization: Normalizes over features and time dimensions for each sample (x.mean(dim=(1, 2))
Reversible Instance Normalization (RevIN): Normalizes across time steps of a sequence for each feature, with reversibility to restore the original input scale (x.mean(dim=1)).
RevIN is a newer method introduced by Kim et al. (2022):

TSMixer also uses Batch Normalization, while TSMixer-Ext uses Layer Normalization. Both variants use RevIN, which is particularly effective for time-series models. RevIN manages distribution shifts while preserving the temporal characteristics of sequences within a batch.
In my custom TSMixer implementation, replacing other normalization methods with RevIN lowered MSE on the test dataset by 1-3%. That’s why many DL forecasting models have started using RevIN.
Since RevIN is a newer technique, you can improve earlier DL forecasting models that didn’t use this normalization type. To use it, normalize each batch before preprocessing and rescale the final output. RevIN can also be combined with other normalization methods like BatchNorm or feature-level global normalization.
Enter TSMixer-Ext
TSMixer-Ext is a versatile Deep Learning model that leverages auxiliary information, such as future known inputs and static covariates, enabling feature-mixing between them. This allows the model to learn complex temporal relationships and produce highly accurate forecasts.
The authors created 3 variants:
TMix-Only (Figure 3)
TSMixer (Figure 1)
TSMixer-Ext (Figure 4)
TMix-Only is a simpler model without the feature-mixing component. It suits cases where individual time series lack dependencies, meaning the model gains no advantage from cross-variate correlations:

TSMixer introduces cross-variate MLPs, allowing it to capture inner-correlations. The authors demonstrate that even in univariate datasets, TSMixer performs comparably to univariate-only models.
TSMixer-Ext further utilizes auxiliary information—future known variables and static exogenous variables:

As Figure 4 shows, TSMixer-Ext builds on TSMixer's time-mixing and feature-mixing components, arranged in 2 stages:
Align Stage: Projects features with varying shapes (historical observed, future known, and static exogenous data) into the same shape.
Mixing Stage: Concatenates the features and applies feature-mixing and temporal projection operations, akin to TSMixer.
TSMixer-Ext is a highly competitive forecasting model. Benchmarked on the popular retail forecasting M5 dataset, it achieves superior results compared to other SOTA models. We’ll discuss this later.
TSMixer vs TSMixer-Ext
The authors refer to both models as multivariate throughout the paper.
In traditional time-series models, multivariate models typically accept historical information Yt-1, Yt-2 of a target variable y with a set of covariates Xt-1, Xt-2, aiming to predict Yt+h where h is the horizon. If the model is trained on a global dataset of N time series, it is called a global multivariate model.
In modern time-series literature, multivariate refers to models that consider cross-variate information—predicting target variables for all individual time series simultaneously. By this definition, TSMixer-Ext qualifies as multivariate.
TSMixer is also a global multivariate model, without auxiliary information. This model takes as input a tensor of size <batch_size, seq_length, num_of_features> where num_of_features represents the individual time series in the dataset (sometimes called channels). The output is <batch_size, seq_length, target_features>, with target_features<=num_of_features.
Multivariate models benefit from cross-variate information as they jointly model all dataset time series. However, they are computationally expensive and should be used selectively. TSMixer still performs well in datasets where cross-variate interactions provide limited value.
In contrast, global univariate models can also include external covariates and are trained globally on multiple time series, but predict one time series (target) at a time. Such models can scale inference by running N instances concurrently for datasets with N time series. Examples include TFT, NHITS, and NBEATS.
GluonTS provides an easy-to-read table that summarizes the important properties of DL models here.
TSMixer Benchmarks
Next, the authors benchmark the 3 TSMixer variants against popular DL models across 2 key benchmarks. Let’s discuss them.
Long-Term Forecasting
This benchmark compares univariate and multivariate models separately on a popular long-horizon benchmark known as the Informer benchmark.
It also provides insights into the efficiency of univariate vs. multivariate models:

The results are quite interesting:
TSMixer is the best multivariate model.
PatchTST is the best univariate model and achieves the top overall score.
TFT is not a native multivariate model. The authors probably stacked the individual time series as features to make TFT work as multivariate. However, this repurposes how TFT’s static encoder vectors should work and that’s why TFT is less competitive here.
TMix-Only performs slightly better compared to TSMixer!
The authors note that simpler datasets in Table 1 favor univariate models due to limited cross-variate information. Using multivariate models for these datasets here may lead to overfitting.
The PatchTST paper also made this finding. However, this may not always be the case. That’s why the authors here decided to test a more complex dataset.
M5 Walmart Kaggle Dataset
This benchmark utilizes the M5 dataset, Walmart’s popular retail forecasting dataset from the M5 competition.
M5 contains 42,840 multivariate time series, each one having historical observations, future time-varying features, and static features.
The features used in this benchmark (including the feature-engineered ones) are listed below:

Initially, models are evaluated using only historical features. To align with the competition, the Weighted Root Mean Squared Scaled Error (WRMSSE) is used:

This time TSMixer achieved the best score, surpassing other popular DL models.
Also, TSMixer outperforms TMix-Only indicating that cross-variate dependencies can benefit a model that knows how to harness their usefulness.
Next, we measure how auxiliary features can improve accuracy. For this task, TSMixer-Ext is used:
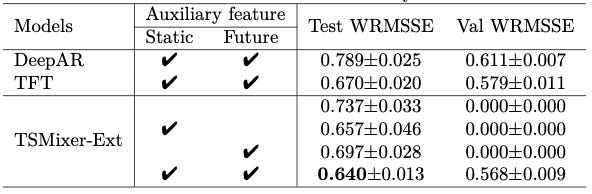
Notice that TSMixer-Ext is used in different configurations here: with and without auxiliary features.
The configuration using both static and future-known inputs achieves the best score.
✅ Note: The authors replaced the final prediction head layer in TSMixer-Ext with one that learns the parameters of a negative binomial distribution. This way, TSMixer-Ext can be adapted for probabilistic forecasting!
Impact of Context Length
A key strength of DL forecasting models is their ability to leverage longer context lengths (lookback windows) for improved performance.
This strength is also evident in modern foundation models like MOIRAI, TimesFM, and Time-MOE.
Naturally, the authors evaluated how TSMixer scales with different context lengths, testing L={96,336,512,720} and comparing it to DLinear in terms of mean squared error (MSE):
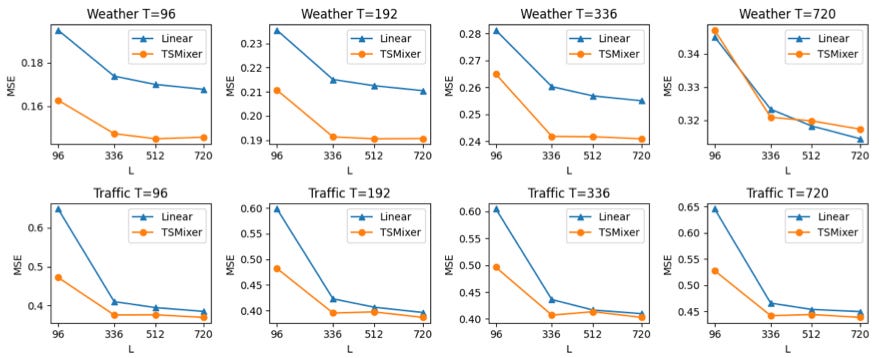
For the datasets in Figure 5, TSMixer consistently improves with larger lookback windows, up to at least 720 data points, surpassing DLinear. By contrast, many earlier DL models struggle to improve beyond ~200 data points.
TSMixer in Practice
TSMixer is available in popular forecasting libraries like NeuralForecast, which also includes an extended version called TSMixer-Ext (or TSMixerx).
The AI Projects Folder contains a Long-Horizon forecasting that compares TSMixer with iTransformer, another popular DL model that captures cross-variate information. Feel free to check it out!

Closing Remarks
TSMixer, developed by Google Research, is a robust forecasting model with 3 variants, each suited to specific use cases.
The largest variant, TSMixer-Ext, excels with complex datasets containing interdependencies, such as those in financial or retail forecasting.
In the recent retail forecasting competition VN1, Temporal Fusion Transformer (TFT) secured 4th place overall and 1st place among solutions without ensembling. Given TSMixer’s superior performance over TFT on Walmart’s M5 dataset, imagine its potential impact in such a competition!
Given that TSMixer outperformed TFT in Walmart’s M5 dataset, imagine how well TSMixer could have performed!
⚠️ Note: There’s a similar model by IBM, also called TSMixer — which is also an MLP-based model and achieves great performance! Don’t confuse these 2 models!
Thank you for reading!
Horizon AI Forecast is a reader-supported newsletter, featuring occasional bonus posts for supporters. Your support through a paid subscription would be greatly appreciated.
References
[1] Chen et al. TSMixer: An All-MLP Architecture for Time Series Forecasting